
Когда я говорю, что машинное обучение в конкурсах и в реальности – это две не имеющих отношения друг к другу вещи – на меня смотрят как на психа.
Задачи на машинное обучение на конкурсах – вопрос оптимизации сеток и поиска лазеек. В редком случае – создания новой архитектуры.

Задачи машинного обучения в реальности – вопрос создания базы. Набора, разметки, автоматизации дальнейшего переобучения.
Задача с кормушкой мне понравилась во многом из-за этого. Она с одной стороны очень простая – делается практически мгновенно. А с другой стороны – очень показательная. 90% задач тут – это не имеющая отношения к конкурсам тягомотина.
База
Как вы, может, помните из первой статьи цикла – мы поставили детектор движения набирать нам базу. Детектор срабатывал на любую шевелёнку. На её начало и на её окончание. В результате работы детектора в течении недели была набрана база примерно в 2000 кадров. Можно считать, что птицы там в каждом втором кадре => приблизительно 1000 изображений птичек + 1000 изображений не птичек.
Учитывая, что точка обзора двигается не сильно – можно предположить, что базы плюс минус достаточно. Попробуем!
Для разметки я написал простенькую программу на питоне.
Версия под винду.
Версия под линукс.
Версии различаются тем, что коды клавы немного разные там и там. Огромное спасибо моей жене за помощь в разметке! 3 часа убитого времени:) Сейчас я не буду заострять внимание на программе. Тем более о теме разметки я уже писал длинную статью на Хабре.
Немножко сосредоточу внимание на том, что размечалось. Для каждой картинки размечалось два признака:
- Тип птицы. Ко мне, к сожалению прилетало лишь два вида синиц. Итого, три типа:
- Птицы нет.
- Лазоревка
- Синица большая
- Качество снимка. Субъективная оценка по шкале [0,8].
Итого, имеем для каждой картинки вектор из двух величин. Ну, например, тут:

Явно качество нулевое (0), а сидит – большая синица (2).
Вот база. Всего по базе получилось примерно половина кадров с птицами, половина пустая. При этом синиц-Лазоревок было всего 3-5% от базы. Да, набрать большую базе – сложно. И да, обучиться по этим 3-5% (~40 картинок) – нереально. Даже ввод батчнормализэйшна на такой простой сетке не даст выделения нужных птичек.
Единственный шанс распознавать их – донабрать базу хотя бы до нескольких сотен. Так что пока вопрос распознавания лазоревок остаётся вдалеке.
Железо + обучение
Как вы, может, помните из прошлой части – мы остановились на том, что полноценная сетка SqueezeNet не влезла в память RPi. Уменьшить её оказалось достаточно просто. Хватило вмешательства лишь в последний свёрточный уровень:
layer {
name: "conv10_BIRD"
type: "Convolution"
bottom: "fire9/concat"
top: "conv10"
convolution_param {
num_output: 3
kernel_size: 1
weight_filler {
type: "gaussian"
mean: 0.0
std: 0.01
}
}
}
layer {
name: "conv10_Q"
type: "Convolution"
bottom: "fire9/concat"
top: "conv10_Q"
convolution_param {
num_output: 3
kernel_size: 1
weight_filler {
type: "gaussian"
mean: 0.0
std: 0.01
}
}
}
Вместо одного уровня на 1000 выходов ImageNet я вставил два уровня по 3 выхода на каждый. Объём занимаемой памяти упал почти в 3 раза. Не совсем понимаю, почему именно так, лень считать каналы:)
В результате не пришлось резать ядра в центре сетки и заниматься полным переобучением. Взял лишь модельку, поверх которой дообучил. Что хорошо.
Итоговая скорость работы на RPi B+ у такой штуки ~ 2-3 секунды на кадр + его предобработку (почистить код от конвертаций лишних, обучить в формате в котором OpenCV напрямую данные принимает – будет 1.5-2 секунды). На RPi 3, на мой взгляд, реально получить realtime (caffe хорошо паралелит обработку по ядрам => приращение скорости близко к теоретически достижимому, а это где-то 15 раз).
За счёт того, что там больше памяти – можно пробовать подтянуть качество.
Почему два выходных слоя? Один на птиц, второй на качество. В реальности, обучения слоя на “качество” – это та ещё морока. Я использовал три подхода (да, можно подходить корректно и брать специальные слои потерь. Но лень.):
- Девять выходных нейронов, на каждом из которых L2 регуляризация (Euclidian). Решение стянулось к центру матожидания. Незачёт.
- Девять выходных нейронов, но по которым разбрасывается не 1-0, а некоторая величина матожидания. Например, для кадра помеченного как “4”: 0, 0, 0.1, 0.4, 0.9, 0.4, 0.1,0, 0. Ошибка по гауссу при таком подходе сглаживает шум в выборке. Обучение более-менее пошло, но точность не понравилась.
- Три нейрона с SoftMax на выходе. “нет птицы”, “птица плохого качества” (величина “0” в метрике качества), “птица нормального качества”(величина “1-8” в метрике качества). Этот метод сработал лучше всего. Статистика средненькая, но хоть как-то работает. Плюс при обучении поставил маленький вес слою (0.1)
С птицами по базе всё хорошо. 88%-90% правильного отнесения в класс. При этом, естественно, 100% потеря всех лазоревок. Но, на первый взгляд, уже приемлемый результат. Так ли это?

Запускаем результат
Запустить всё просто. Берём наш старый детектор движения, добавляем к нему Caffe:
if (d>20):
frame = frame[:, :, [2, 1, 0]]
transformed_image = transformer.preprocess('data', frame)
net.blobs['data'].data[0] = transformed_image
net.forward()
if (net.blobs['pool10'].data[0].argmax()!=0):
misc.imsave("base/"+str(j)+"_"+
str(net.blobs['pool10_Q'].data[0].argmax())+".jpg",frame)
j=j+1
else: #ЗАЧЕМ?!
misc.imsave("base_d/"+str(k)+".jpg",frame)
k=k+1
Кто-то спросит “а зачем детектор движения”? Или даже: “а зачем тут else?!” Ответов два:
- 2 секунды на кадр – это достаточно медленно. Добавка детектора ускоряет отклик на кадр – значительно. Всё равно все интересные события происходят +- в окрестности движения
- Набор базы!
Как набор базы!? А что же мы раньше делали?
Раньше мы набирали обычную базу. А теперь – мы набираем базу ошибок. За одно утро сетка выдала более 500 ситуаций распознанных как синицы:






Но позвольте! Может ваша сетка не работает? Может вы перепутали каналы, когда передавали изображение к от камеры к сетке?
К сожалению нет. Это судьба всех сеток обученных на малом объёме данных. В тренировочном сете было всего 6-9 позиций камеры различных. Мало засветок. Мало посторонних шумов. А когда сетка видит что-то совершенно новое – она может выкинуть неверный результат.
Но это не страшно. Ведь мы прикрутили сбор базы. Всего 300-400 пустых кадров в нашу базу – и ситуация улучшается. Вместо 500 ложных тревог за утро их уже ноль. Только вот что-то и птичек продетектировалось всего 2/3 от их общего числа. А вот этих не распознало:


Ну да. Для этого есть сбор базы на обычном детекторе движения. И статистика уже набирается.
Знающий человек, который разбирается в конкурсах может сказать: “К чему вся эта пурга! Вы неправильно разбили базу на тестовую и тренировочную, нужно чтобы сэты данных (в данном случае положения камеры) не пересекались в тестовой и в тренировочной!”.
И действительно. Это более правильная концепция. Только вот не обучиться модель и что? Ведь она же не будет устойчива потом и к другой смене положения камеры. Может мы сразу увидим, что у нас не 88%, а 70%. Но разбить датасеты таким образом зачастую труднее или совсем невозможно. А главное – нет смысла. База то маленькая. И из неё нужно выжимать всё.
Процесс решения задачи работы != процессу создания оптимальной сети. Сеть вторична – база первична. Первые итерации сети должны не решать всю задачу целиком, а оптимизировать дальнейшее внедрение и разработку. Всё равно будет итерация. А может и не одна.
Реальное внедрение системы – это постоянный рабочий процесс, где сетку приходится подкручивать каждые несколько дней. А иногда и внедрять дополнительные механизмы:
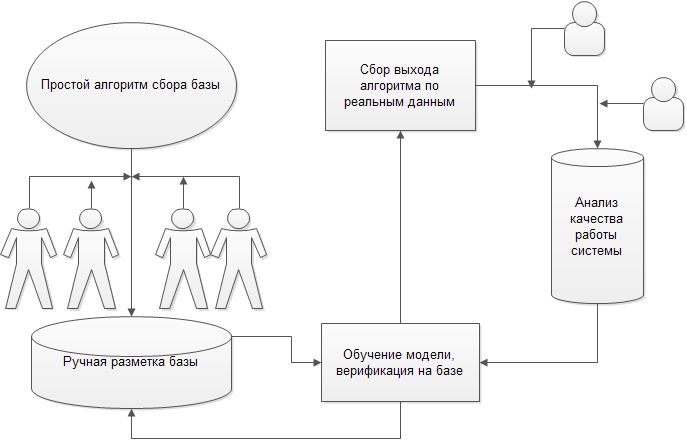
Решение задачи на практике – это построение такой схемы, со всеми процессами дообучения, переобучения, сбора и оптимизации сбора.
Так что с птичками?
Всё ок! Для первичной системы качество меня устраивает. 2/3 правильных обнаружений это уже нормально. Сейчас мне хочется:
- Набрать достаточное число ошибок первого и второго рода и дообучить систему. При таком подходе (обучение на ошибках) размер базы можно значительно уменьшить (мне кажется, что 400-500 ошибок значительно улучшат качество системы)
- Набрать достаточное число лазоревок, чтобы было хотя бы 2 типа птичек (в идеале кадров 400, хотя это дохрена)
- Обвязка для вывода результата
Код на гитхабе обновил: разметка, обучение, тестирование, тестирование на RPI, сбор базы
В базу выложил размеченную базу.