
Сегодня утром пока просыпался прочитал странные заголовки про Caffe2. Помедитировал над парочкой статей с маркетинговым булшитом – и пошёл разбираться что же это всё-таки такое на самом деле. Всё же 90% текущих проектов именно на Caffe. Надо быть в курсе всё же.

Берётся это чудо вот отсюда. Судя по описанию – это проект facebook, правда сегодня были анонсы от NVIDIA и от INTEL что они участвуют в проекте.
NVIDIA, которая давно имеет свои форки Caffe судя по всему завезла оптимизации, а Intel рассказывает о нативном MKL. Судя по всему OpenCL не завезли и AMD в пролёте (поиск по проекту и инету ничего не даёт). Это немного странное решение, учитывая что постулируется высокая кроссплатформенность решения, а форк Caffe под OpenCL существует давно.
Ещё немного маркетингового булшита – Амазон уже развернул на своих серверах. Qualcomm уверяет о полноценной поддержке их процессоров.
За рамками остаётся вопрос – насколько Caffe2 – продолжение официального Caffe, а насколько форк.
Дальше – по делу.
Есть шанс, что в тексте будет много косяков. Всё это – первые впечатления от доков, сорсов и 5-10 запусков представленных экзамплов.
Первый логичный вопрос: в чём отличие Caffe2 от текущего Caffe?
Основное отличие в том, что в Caffe объектом был “слой”, а теперь объект “оператор”.
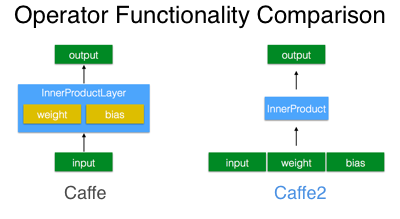
Сделано это, понятно, чтобы разрешить основную проблему существующего Caffe – невозможность построения интерактивного “графа” сети. Caffe исходно был разработан в стиле “вот сеть, её можно исполнить сразу и целиком”.
Тут подход ближе к TensorFlow. Выстраивается цепочка исполняемых операторов, которую можно по ходу обучения сдвигать/исполнять в другом порядке.
Это, безусловно, плюс. Но при этом выглядит это после Caffe ужасно. Например ApolloCaffe, который это реализовывал – был куда понятнее после Caffe.
Тут же пол часа запусков примеров не дало мне понимания как при дебаге найти текущие значения блобов внутри структуры workspace.
Хотя команды
workspace.FetchBlob('data')
Должны их выдавать. Но в caffe всё было прозрачнее.
В целом, ощущение, что если захочется мигрировать на Caffe2 – все обёртки доступа к сети, загрузки/выгрузки данных, запуска, и.т.д – придётся заново писать.
Плюс, судя по всему, будет куча стороннего мусора, который раньше сетка брала сама на себя. Например сейчас вам нужно следить за тем где стопнуть градиент (StopGradient). Или вручную конструировать тренировку на верхнем слое. Раньше это можно было делать. Но в 95% случаев это происходило автоматически – не нужно было думать как это обставить.
С одной стороны, наверное, ничего особо сложного, но размер кода существенно разбухает, повышается порог входа. В примере про MNIST у авторов получился такой итоговый вид сетки:

MNIST. LeNet. По-моему это перебор.
Чем-то напоминает Theano 2-3 летней давности.
Итоговые минусы, суммирующие пару абзацев выше:
Минусы
–Несовместимость со старой идеологией, старый код нужно менять в корне
–Судя по ощущениям значительно увеличивается размер программы, повышается сложность
–Низкое качество проработки структуры проекта (папки с экзамплами валяются не весть где, непонятно куда сохраняются сетки скачанные, и.т.д.)
–Низкое качество экзамплов. Экзамплы не работают в варианте “Click’and’go”. Приходится самому додумывать что же ему нужно. Пока их мало.
А теперь всё же разберём, почему Caffe2 не пустой проект и чего в нём хорошего.
Плюсы
+Большое число платформ даже в базовом варианте

Плюс – уже готовые скрипты установки на RaspberryPi (хотя не всё так радужно).
+LSTM, RNN и прочие, недоступные Caffe примочки
+Зашитая в корень возможность тренировки на нескольких карточках/на нескольких машинах. Мне сложно сделать подробный обзор этого функционала с наскока. Но судя по всему – значительно удобнее чем в Caffe реализовано.
В Caffe из питона нельзя было запустить такую тренировку, а версия c++ была несколько ограниченна.
+Собранная в одном месте документация и примеры. У Caffe это была серьёзная проблемма. Большая часть информации шла через форумы/переписку GitHub. Есть шанс, что тут будет сделано не хуже чем в TensorFlow.
+Простота сборки/установки по сравнению с Caffe/сложность по сравнению с TensorFlow
Краткое резюме.
Мне кажется, что проект имеет право на жизнь. Основной вопрос – насколько смогут перетащить пользователей современного Caffe на него. Если перетащат хотя бы половину, при этом Facebook будет поддерживать проект и вливать в него средства – это может стать реальным конкурентом TensorFlow.
Если же народ не будет переходить с Caffe – то сообщество окончательно развалиться и уползёт в сторону других проектов.
В текущем варианте мне проект кажется слишком угловатым и не отлаженным. Понятно, что это всё лечиться. Но нужно смотреть, насколько проект будет готов к критике, насколько просто будет срезать углы, насколько быстро появятся экзамплы.
Если вы делаете обычную сетку по сегментации/классификации/распознаванию – то проще сделать на обычном caffe.
Если же вы хотите добавить чего-то рекуррентного и не охота лезть в TensorFlow – то caffe2 – интересный вариант.
И да, самый сильный момент – продакшн. Для него всё подготовлено и настроено. Мне кажется, что тут сложены основные силы. И это самая сильная черта текущего Caffe.
А может я повёлся на маркетинговый буллшит:)