

Computer Vision достаточно необычная область. Далеко не все алгоритмы из машинного обучения сюда заходят быстро, далеко не все приживаются. Примером того, что я не видел в варианте “в кассу” – были Graph Neural Network (GNN – сети работающие на графах).
Но, внезапно натолкнулся, об этом и рассказ.
Пару слов о том что такое GNN. Я не эксперт по этой области ML, так что могу достаточно неполно объяснить всю картину. В моём представлении GNN – это узловая классификация. Если каждый узел в графе ассоциирован с лэйблом, то такая сеть учиться предсказывать лэйбл исходя из положения на графе и соседней у которых есть лэйблы. Более подробно можно почитать про эти сети, например: 1, 2
Сегодня эти сети используются в массе задач. Чаще всего это какие-то задачи построения рекомендательных систем, задачи моделирования лекарств, задачи анализа транспорта, и.т.д. По сути любые задачи где есть сложная структура по которой надо ползать.
Но за последние несколько лет я ни разу не встречал хорошего применения этих нейронок на практике. Конечно, были попытки натянуть ежа на глобус (про них я расскажу чуть ниже). Но такого же логичного внедрения как заходили прочие методы я не видел:
- SVM, AdaBoost и решающие деревья мы регулярно использовали до появления нейронок
- Всякие LSTM и прочие рекуррентки мы использовали в 3-4 проектах
- Про модные Transformer’ы я недавно писал, но на практике не использовал
- Разные embeding-репрезентации и прочие скрытые пространства используются налево и направо, даже и не заметно, что это неклассические штуки для CV когда-то были
Еж на глобус
Я специально прогуглил, были ли крутые использования GNN в CV. Я не смог найти ничего реально полезного, но про пару сэмплов расскажу:

Использование графа для распознавания. Во мне – шиза сумрачного гения. Не, я понимаю, что сработает. Но зачем? Нет никакого теоретического преимущество, а точность ниже.
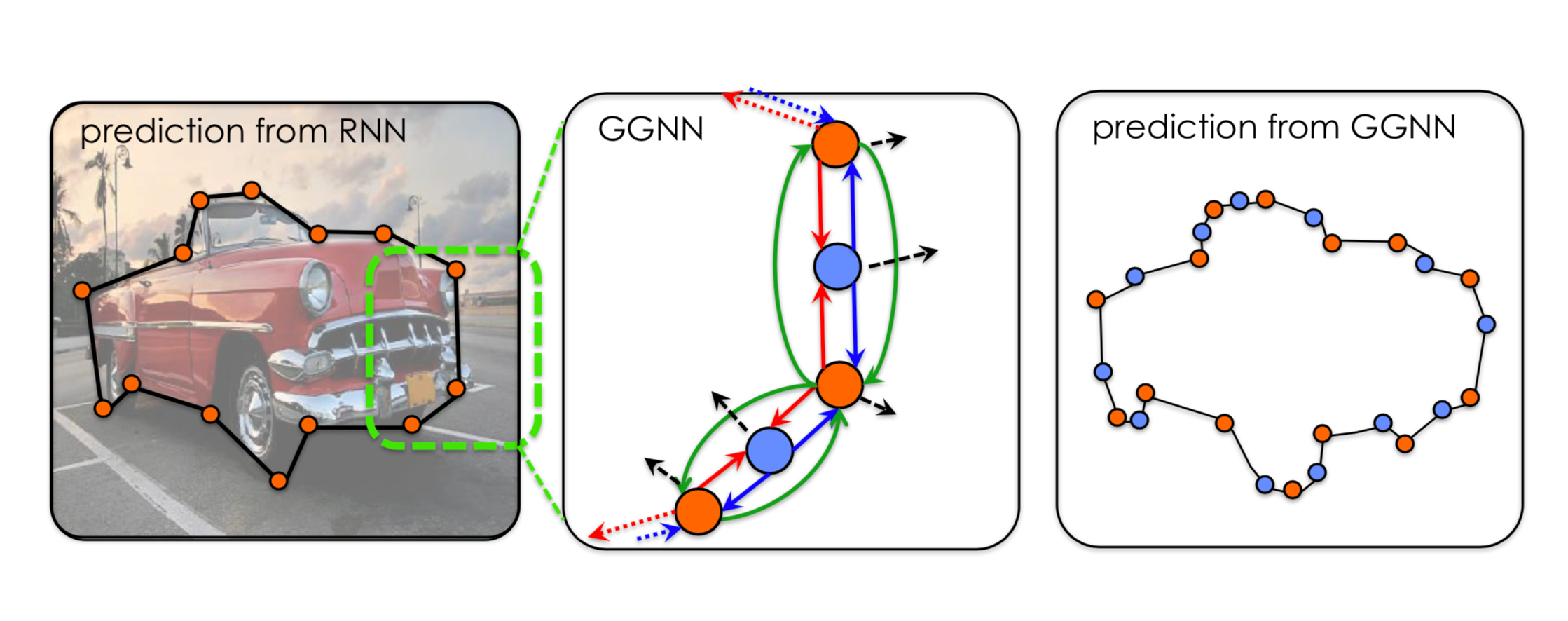
Сглаживание различных контуров или детекций через графы. Например: 1, 2, 3. Выглядит уже приличнее, но почему-то мне кажется, что на практике никто так не будет запариваться. Тем более я не видел ни в каких серьёзных практических бэнчмарках этих подходов в топе.
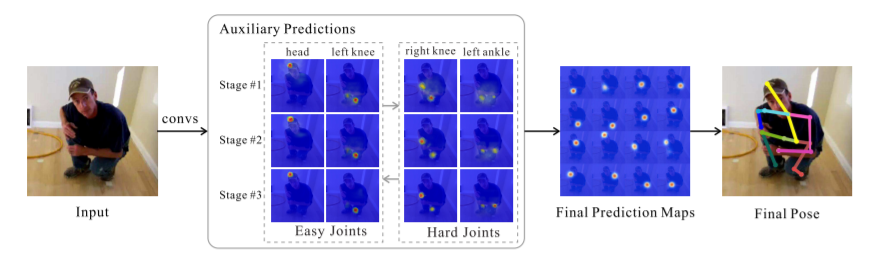
Есть интересная работа про распознавание скелетов. Но бэнчмарки слабые (не встретил в них ни одной популярной работы), работы с большим числом поз нет, тестируется только на одном датасете.
Если знаете что-нибудь интересное – пишите!!
Что понравилось
Наконец нашёл прикольную нейронку, которая использует GNN. Называется SuperGlue: Learning Feature Matching with Graph Neural Networks . И, как ни странно, это:
- Неплохая работа в области где последние 10 лет не было ни одного серьёзного улучшения
- Применение нейронной сети в области где до сих пор не смогли прикрутить хорошую нейронную сеть (за последний год есть некоторые подвижки, возможно сделаю на эту тему видео позже)
- Достаточно простое и нативное решение, чтобы интегрировать это в реальности.
Сама задача – очень старая и известная. Извлечь фичи из нескольких изображений и найти их взаимное соответствие. Обычно это решается через три этапа:
- Выделить фичи и рассчитать их дескрипторы
- Оценить отношения дескрипторов/все со всеми
- Методом RANSAK найти взаимное соответствие между изображениями
Статья SuperGlue позволяет заменить последние два эапа:
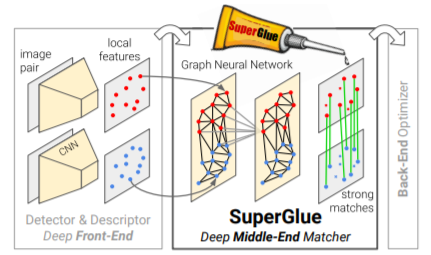
Детекция дескрипторов по прежнему осуществляется нейронной сетью (авторы используют SuperPoint, но подход работает и с классическими дескрипторами).
SuperGlue это по сути построение графов на задетектированных точках (на одном изображении и между разными изображениями).
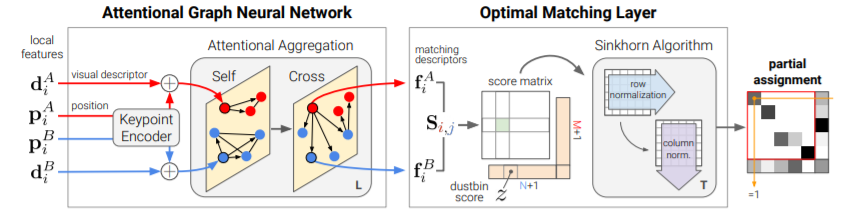
Конечно, поверх ещё натянут Attention и дополнительный слой кроскорреляции, но это выполняется единым end-to-end алгоритмом.
Судя по тому что пишут в разных отчётах – метод действительно выглядит рабочим, и позволяет как-то проапдейтить классический RANSAK-подход.

Возможно, GNN когда-нибудь станет таким же стандартным подходом как RNN. Но пока видна лишь первая ласточка.
PS
Чуть более полный разбор про современные подходы в задачах совмещения двух изображений (через особые точки, или через сдвиг) делал тут –
З.Ю.
В последнее время свои статьи я публикую на очень разных платформах.
И, так получилось, что единое место куда я их свожу тут – https://vk.com/cvml_team (дублирую в https://t.me/CVML_team )
Тот проект в рамках которого всё это сбадяжил – буду на Хабре публиковать скорее всего. Так что ссылка тоже только там будет.
Так что советую подписаться!