
Мне всегда любопытно наблюдать как движется развитие нейронных сеток и искать какие-то соответствия тому, как обработка инфы устроена в мозгах. Особенно прикольно в этом отношении смотреть на пост-ResNet сети. Вроде как и хороший результат, но привязки к мозгам – никакой. Просто экстраполяция идей. Residual connection заработали? Ладненько, ладненько. Как мы можем запихать ещё кучу в нашу сетку?
Вставить Residual connection внутрь Residual connection? (Resnet in Resnet)
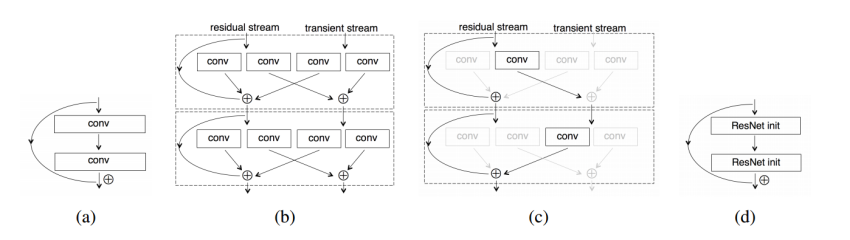
Или собрать ResNet сетку из нескольких ResNet сеток? (Multilevel Residual Networks)
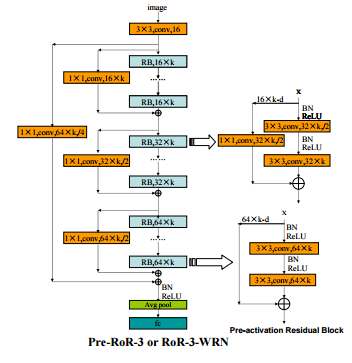
А может вообще не париться и соединить через Residual connection каждый слой с каждым? (DenseNet)
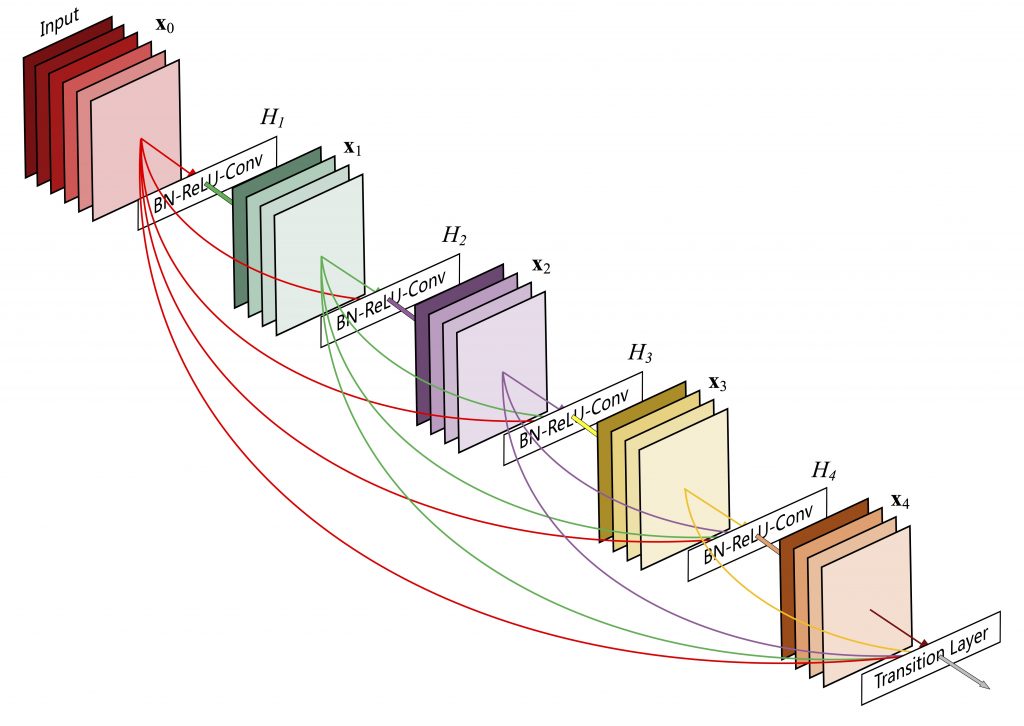

(ну, вообще, конечно, тут не каждый с каждыми, а небольшими группами по 5 слоёв).
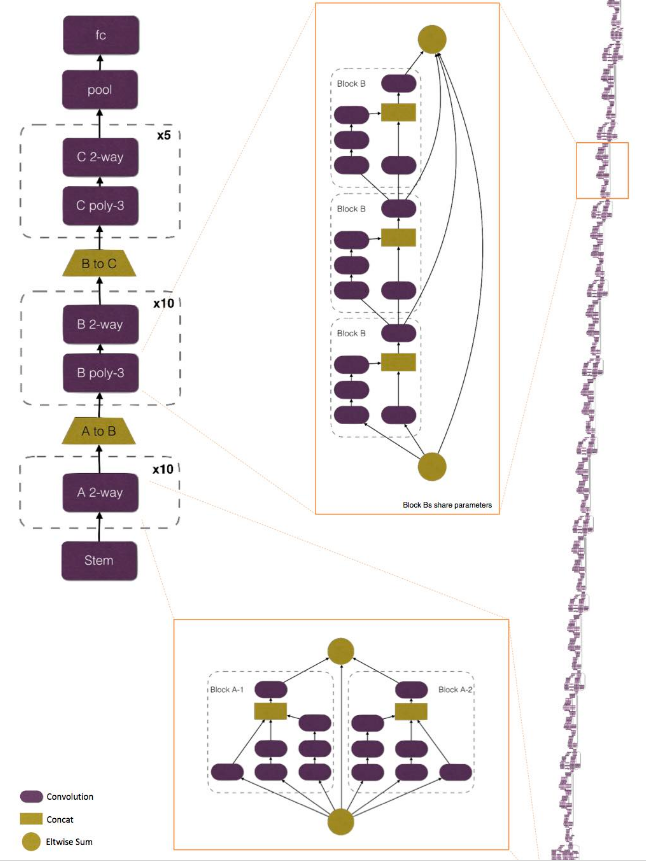
А если есть штук 8 титанов, то можно сделать такую сетку, чтобы всю память забивала. И всю из ResNet-ов! (PolyNet)
Хоть каким-то глотком свежего воздуха на всём этом фоне видится FractalNet.
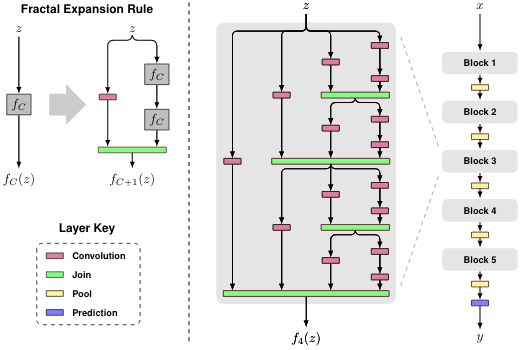
Тут хотя бы попробовали переосмыслить старую идею “DropOut”, которую после появления ResNet уже вроде как выбросили из рассмотрения, а теперь она возвращается при обучении разных цепочек внутри фрактальной сетки.
Мысли.
Вот смотришь на всё это многообразие и думаешь:
- Какая польза от всего этого на реальных задачах? Или требуются безумные ресурсы на обучение и использование? Видишь что CIFAR 100 обучают на 3-4 титанах. И пичаль.
- Есть хоть какое-то сравнение по эффективности, по ресурсам, по времени обучения, и.т.д.? Ведь каждый публикует сравнение по тем фреймворкам, которые ему удобнее. И никому неинтересно показать эффективность на каких-то практических задачах:
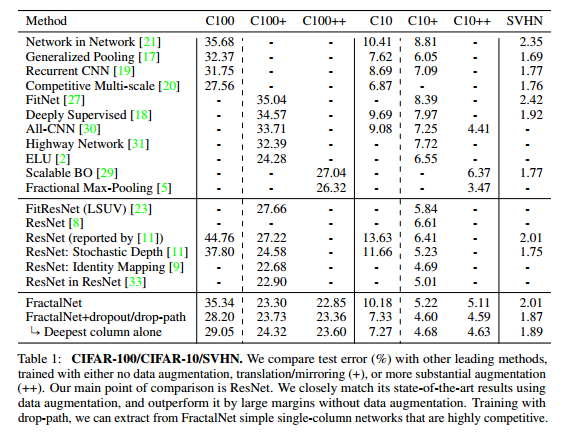
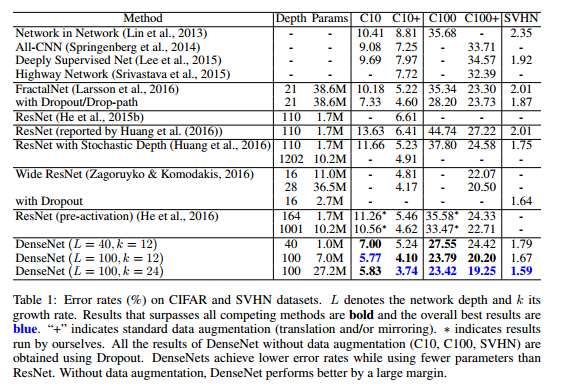
И ни одного внешнего годного исследования. Максимум “вау, вот такая сетка есть” (ну, это то же самое, что и я тут пишу). - Почему практически никто из этих сеток не представлен в “ImageNet” текущего года? Почему в десятке лучших решений просто оттюнингованный ResNet? Может всё это сверх-residual хозяйство становится неприменимо для задач отличных от CIFAR?
“…развитие нейронных сеток и искать какие-то соответствия тому, как обработка инфы устроена в мозгах.”
“…безумные ресурсы на обучение…”
Если тупо количество синапсов в мозгах сравнить с количеством транзисторов в 10 шкафах по 14 DGX-1 в каждом, в каждом из которых по 8 Tesla P100 на каждом из которых прямо на той же подложке по 4 четыхехслойных памяти HBM2. То получится, что где-то на порядок больше синапсов в мозгах. Правда частота в чипах около полтора гигагерца – на несколько порядков больше, чем в мозгах. Но время обучения у мозгов – лет 10 до уровня третеклассника – на несколько порядков больше, чем обычно отводится компьютерам. Так что по времени/частоте паритет примерно есть, но есть и куда расти. А по количеству транзисторов надо еще расти и расти. И надо беспощадно забивать эти транзисторы чем угодно – моя люимая тема – это всякие монте-карлы типа AlphaGo. И всякая диффиренцироспособная ассоциативная память типа Differencial Neural Computer. Но я бы их конечно беспощадно раздул бы в размерах. На больших размерах можно и более тонко поиграться.
Еще обучается наверное. Тот же xception несколько месяцев обучали, уже вышла статья по инцепшн4 а они ссылаются на 3ий 🙂