
На выходных учил жену кататься на беговых лыжах (она второй раз в жизни на них встала). И у нас возник забавный спор про теорию обучения. “Отталкиваться палками, – говорю, – нужно непрерывным движением, направленным вдоль тела сверху-вниз, назад. Вот смотри, у тебя палки загораживают лыжи во время такого действия – значит ты что-то делаешь неправильно. Старайся не допускать такого”. Жена же у меня – хирург. И таких объяснений не понимает. “Скажи мне лучше, какими мышцами толкаться. Вот ты делаешь это движения, что ты используешь?”. И тут в ступоре уже я. Я не врач. Я даже не знаю, где у меня мышцы и чем я толкаюсь.

Зато я понял, что ровно такой же казус встаёт при обучении нейронных сетей. Сеть можно обучать набором внешних умозрительных правил, расставив там Softmax/EuclidianLoss. “Видишь что рука заслонила лыжу – попробуй сделать что-нибудь по-другому”. А можно заложить куда более глубокую модель в которой персонализировать цену ошибки каждого конкретного случая. “Если запущена сначала мышца 1, а потом мышца 2 – ошибка”. Тут, конечно, сложнее. Нужно придумать такую модель. Зато эффективнее. В статье – небольшая подборочка интересных решений, которые мне попадалась и которые били существующие по эффективности за счёт персонализации функции потерь.
Первый пример по истине офигенный. Есть стандартная задача “найти все объекты в кадре”. Это могут быть лица, могут быть машины, могут быть товары, могут быть какие-то жучки-паучки. Для плюс-минус для решения этих задач есть десятки сетей: YOLO, SSD, Faster-RCNN, DIGITS, и.т.д.
Но у всех таких сетей есть один трагический и неустранимый минус. При большом числе объектов – они сходят сума:

Обычно такие сети имеют на выходе уменьшенную раз в 10 картинку, где в каждой точке описана гипотеза наличия там объекта. Если же в одной области пространства несколько объектов – это печаль. Иногда сеть может правильно справиться и выдать обе гипотезы. Но когда число объектов увеличивается – фэйл растёт в размере. То, что тут изображено – ещё не самый ад, свойственный таким сетям.
Но ребята написали офигенную статью, даже не поняв своей офигенности. Входом их функции потерь являются 50 гипотез формата “X, Y, W, H, P”, где P – вероятность нахождения объекта, а остальное – его параметры. Сама функция из двух этапов. Первый этап – решение классической задачи целераспределения:
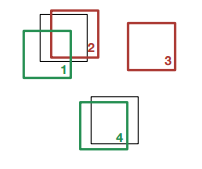
Есть два набора прямоугольников – C и G. Нужно найти соответствие одного набора и второго. Задача классическая и решается перебором. Сложность N^3. Используется венгерский алгоритм. По сути, минимизируется функционал:
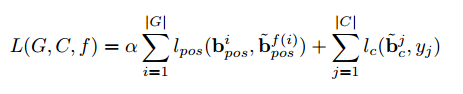
Первая часть – на сколько нужно сдвинуть прямоугольник, чтобы он попал на целевое положение, вторая часть – штраф за ложный прямоугольник.
Получив набор соответствий генерируется функция потерь для каждого из нейронов входа. Код не самый простой, но в 200 строчек помещается. Результат потрясающий:

Попробовали эти идеи в реальных задачах – работают классно. Разница нереально большая.
Второй пример – это многочисленные сетки по распознаванию лиц. Идея всех сеток одинаковая: при обучении сделать бутылочное горлышко, на 128-512 нейронов. А после горлышка сделать вывод на 10-20 тысяч лиц. В результате в bottleneck слое появится некоторая универсальная репрезентативная модуль лица. Некоторый базис. 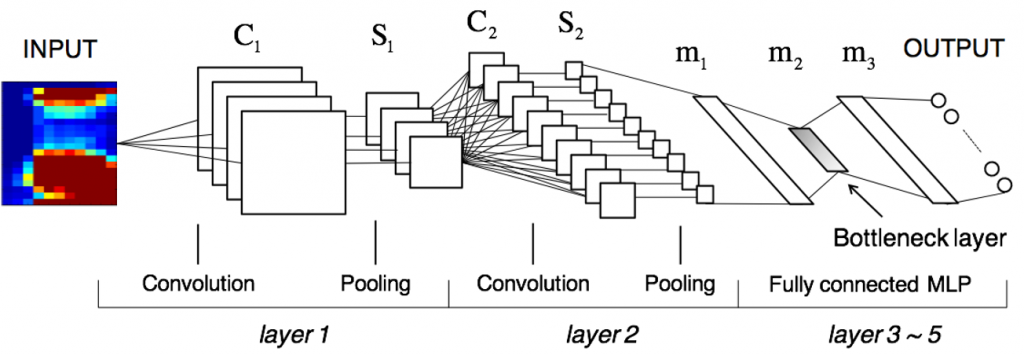
При этом на выходе можно использовать обычный SoftMax (DeepID 14ого года). А можно подойти со стороны задачи. Задача в том, чтобы похожие лица выглядели похоже.
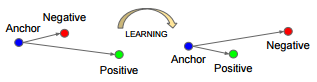
Первая идея, которую предложил Google (FaceNet) в своей статье – введение TripleLoss. Идея заключается в минимизации функционала, который обеспечивает максимальную дальность между разными лицами и минимальную между одинаковыми:
При этом функционал выглядит как:
![]()
И именно этот функционал выведен в слой потерь. Мы выбираем такую функцию спуска, чтобы он был минимальным.
Вторая идея, из другой статьи, опять же строит функцию потерь вокруг задачи. Тут функция потерь настоятельно рекомендует сети держаться как можно дальше от “среднего лица” и как можно ближе к своему “среднему”. Это вынуждает сеть выбирать такой набор признаков который будет максимально далёк от его усреднённого значения, а значит никакое лицо не будет “средним”, а значит все будут различаться. Конечно, это более далёкая постановка задачи, чем “Triple loss” от Goggle. Но за счёт того, что обучение более простое – сильно более выгодное.
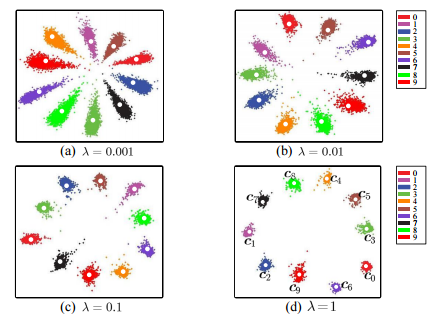
Минимизируется функционал:
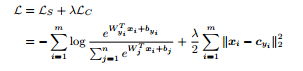
Тут можно сказать “Уууу, это всё сложно”. Но в реальности – не особенно. Такой слой зачастую можно написать в несколько строчек. Для Centrall Loss: апдейт средних весов при прямом пропогэйшоне.
__global__ void Compute_distance_data_gpu(int nthreads, const int K, const Dtype* bottom,
const Dtype* label, const Dtype* center, Dtype* distance) {
CUDA_KERNEL_LOOP(index, nthreads) {
int m = index / K;
int k = index % K;
const int label_value = static_cast<int>(label[m]);
// distance(i) = x(i) - c_{y(i)} - единственный апдейт дистанции
distance[index] = bottom[index] - center[label_value * K + k];
}
}
И вычисление ошибки при обратном:
__global__ void Compute_center_diff_gpu(int nthreads, const int M, const int K,
const Dtype* label, const Dtype* distance, Dtype* variation_sum,
Dtype* center_diff) {
CUDA_KERNEL_LOOP(index, nthreads) {
int count = 0;
for (int m = 0; m < M; m++) {
const int label_value = static_cast<int>(label[m]);
if (label_value == index) {
count++;
for (int k = 0; k < K; k++) {
variation_sum[index * K + k] -= distance[m * K + k];
}
}
}
for (int k = 0; k < K; k++) {
center_diff[index * K + k] = variation_sum[index * K + k] /(count + (Dtype)1.);
}
}
}
И это все изменения, которые придётся внести! Дальше “center_diff” напрямую отправляется в потери на bottom.
Разница с статьями, где просто обучают “бутылочное горлышко” без специализированных потерь где-то 2-3%, что для задач биометрии – очень много.
Куча работы в последнее время, так что на блог подзабил. Работа, конечно, вся по тематике. Когда переварю всё – разражусь серией статей. Много полезного опыта было.
Добрый день, Антон!
Спасибо за интересный блог. Надеюсь он станет хорошим дополнением к вашим хабровским статьям.
И вопрос: что посоветуете чтобы научиться писать слои под каффе, в том числе на cuda? Курсы, туториалы? Где вы сами это изучали?
Эмм… Не видел ничего такого:)
Всегда когда что-то нужно было сделать – просто сам ковырял, пробовал переделать из чего-то похожего. Там всё логично:)
Посыл про функции потерь очень правильный!
Когда мы решали задачу определения возраста людей, то тоже столкнулись с проблемой:
1. Регрессия стягивается к среднему значению
2. Если использовать softmax, то возраст нельзя считать независимыми классами и одинаково штрафовать за неправильную классификацию с разницей в 1 год и в 50 лет.
В качестве решения мы использовали размытую по гаусу функцию потерь для софтмакса и немного переписали сам софтмакс.
Позже увидели, что эту идею используют ребята занявшие второе место в конкурсе LAP challenge
Так же любопытным показалось использование IoU функции потерь для точного определения положения объекта при детектировании
Из embedding learning (лица и прочая верефикация) полезной метрикой показалась метрика magnet loss, в которой обучается метрика кластеризации, а не отношения между конкретными примерами
Мне это напоминает то, как люди вручную хэндкрафтили фичи лет 7 назад:)
Любопытно, а почему с лицами не заработал какой-нибудь EuclidianLoss, который штрафует за дальность? В задачах поиска какой-нибудь геометрии, где ошибка была пропорциональна дальности он неплохо заходил.
Что такое IoU?
Magnet Loss посмотрел, оно близко к center loss вот в этой статье – http://ydwen.github.io/papers/WenECCV16.pdf про которую я упомянул. С другой стороны, идея понятная вполне.