
Всегда когда я разговариваю с человеком который хочет сделать новую систему распознавания я рассказываю о том что машинное обучение неидеально. Что всегда есть ошибки. Что всегда что-то будет идти не так. И что цель – не обучить один раз систему распознавания. А цель – выстроить систему которая будет стабильна к любым ошибкам распознавания.
Обычно показываю примеры наших работ (ну, сходу вот тут то как такое делается – 1, 2, 3, 4). Мы обычно называем это “Human-Machine colloboration”.
Показываем как другие фирмы такое делают – supervisely, figure-eight (humans-in-the-loop), deep brain. Ну, я не буду упоминать про такие платформы как Толока, МеханикалТурк.
Но все и всегда говорят одно и то же:
“Да нам это не нужно! Нам просто модель обучить. Всё это не нужно! Пользователи сами ошибки разберут! Вы нам сделайте точность 95%, этого хватит”.
И всегда приходится рассказывать и объяснять какие последствия будут приносить ошибки пользователям именно в их случаях. Но страх перед ручным трудом – поразителен.
Слава богу в последнее время появилось несколько офигенных примеров в которые теперь удобно тыкать носом и говорить “вы думаете вы умнее гугла/яндекса/амазона/эппла/теслы?”:)
Про Google|yandex|amazon и apple всё просто. Без постоянного человеческого контроля качества никакое голосовое распознавание не работает. Всегда есть ошибки, корнеркейсы. Надо создавать системы которые позволяют вытащить их всё больше и больше. Проверять что колонка грамотно реагирует на активацию. Проверять что корректно распознаёт текст и акценты. Проверять что релевалентно запускает поиск.
А с Tesla всё неимоверно интереснее. Тесла выпустила запись своего общения с инвесторами. И тут безумно круто рассказано как выстроен функционал обучения системы:
Понятно, что Андрей Карпаты – очень классный специалист в DL. И тут просто было бы интересно послушать про алгоритмы. Но главное что он рассказал – это про то как выстроена система сбора данных и обучения. В своей жизни я встречал 6-7 примеров хороших и добротных систем, где есть обратная обработка данных, дообучение на примерах, оценка целевого качества. Где-то 2-3 из этих систем внедрили мы сами. Но настолько классную, и продуманную систему вижу впервые.
Да, понятно, что очень многое Андрей не расказал. Что-то можно додумать. Что-то является ноу-хау и про них умолчали. Но что-то из рассказанного офигенно. Например то, как происходит сбор примеров.
Как только оператор замечает хоть одну ситуацию которая нетривиальная и некорректно описывается текущими алгоритмами (например велосипед прицепленный к машине):

Одного примера хватает чтобы запустить автоматический сбор таких же примеров всем флотом автомобилей Tesla по всему миру:


И полученные изображения аннотируются людьми вручную, проверяются что они реально содержат спорную ситуацию, добавляются в обучение. Так собираются не только статичные, но и динамичные сцены. Короче задействуется ровно тот же механизм с которого я начал:
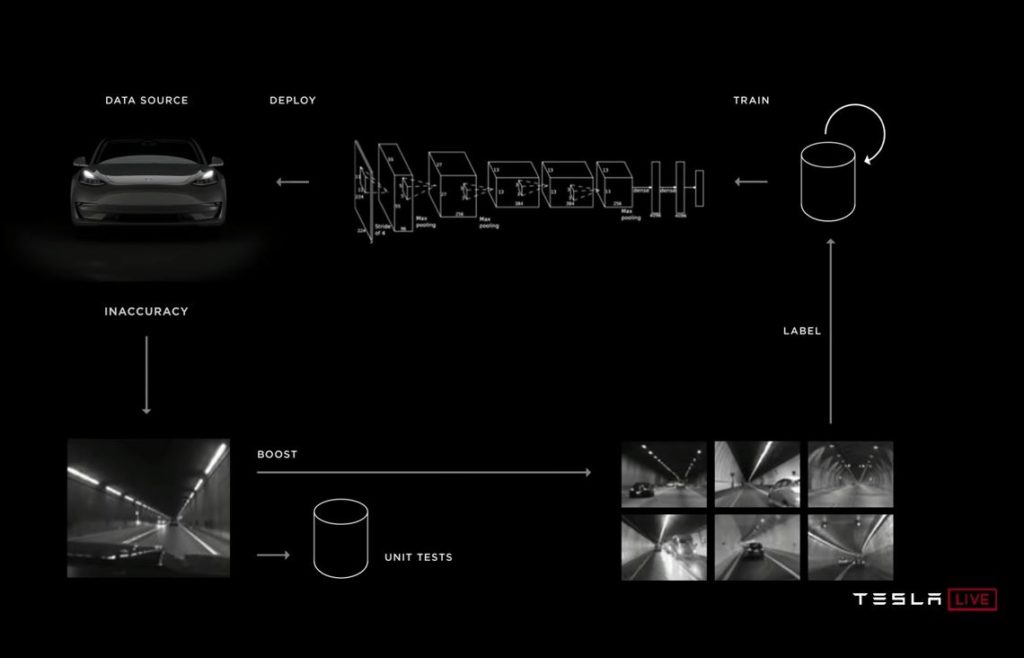
Сколько вы видели аварий в своей жизни? А с авто Tesla вы можете собрать их миллионы. Это вам как видеорегистраторы в России, только сеть!
В целом в видео есть пара ещё неплохих инсайтов (симулятор, сравнение с лидарами, и.т.д.). Но самое главное – офигенный пример выстроенной системы, в картинках, с интеграцией и с операторами. Не поленитесь посмотреть! А я буду слать его всем заказчикам которые захотят убедить меня что ручной лейблинг и постоянная оценка качества системы человеком не нужны:)